Prof. Jan Bosch
This week, I attended the International Conference on Software Business (ICSOB 2020) and gave a presentation on autonomously improving systems. The core idea is that software-intensive systems can measure their performance, know what to optimize for and can autonomously experiment with their own behavior.
The history of software-intensive systems can be divided into three main phases. In the first phase, we built systems according to a specification. This specification could either come from the customer or from product managers, but the goal of the R&D team was to build a system that realized the requirements in the specification.

Many online companies, but also the first embedded-systems companies, are operating in the next stage. Here, teams do not get a specification but rather a set of one or more prioritized KPIs to improve. In e-commerce, the predominant KPI often is conversion; in embedded systems, often a weighted mix of performance, reliability and other quality attributes is used. Teams get as a target to improve one or more of these KPIs without (significantly) deteriorating the others. They have to develop hypotheses on this and test them in the field using, for instance, A/B experiments.
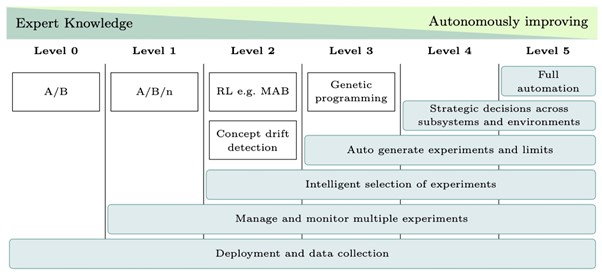
Although the second stage is a major step forward for many companies, the problem is that it still is the team doing all the heavy lifting. Especially running many A/B experiments can be quite effort consuming. The next step that some companies are starting to explore is to allow the system to generate its own experiments with the intent to learn about ways to improve its own performance. Theoretically, this falls in the category of reinforcement learning, but it proves to be quite challenging to realize this is an empirical, industrial context.
The evolution companies go through to reach this third stage can be put in a model, showing the activities and technologies that can be used at each level. From level 2, we see some autonomously improving system behavior such as adding intelligent, online selection of experiments, as well as automatically generating experiments. This results in all kinds of challenges, including predicting the worst-case performance of the generated alternatives. If a system autonomously generates and deploys experiments, some of these experiments can exhibit very poor performance, meaning the system requires models to predict the worst-case outcome for each experiment, as well as solutions to cancel ongoing experiments if performance is negatively affected.
'We need to start looking into online reinforcement learning'
With the increasing prevalence of AI, we need to start looking into online reinforcement learning in software-intensive systems as this would facilitate autonomously improving systems. This ambition comes with major challenges that we’re now researching. However, I encourage you to start exploring where the systems that you build could autonomously improve their own behavior. Even starting in a small, risk-free corner of the system can be very helpful to learn about this paradigm. The overall goal is that every day I use your product, I want it to be better!
Keep up to date
Receive our monthly updates

